


In the current competitive scenario, shopping is shifting to a hassle-free and comprehensive product variants environment which is E-commerce. If you are running an e-commerce business you might feel that you need some kind of Amazon Data Scraper with which you can move ahead from the competition. As E-commerce is booming the competition is increasing exponentially, one can have an edge if they can leverage technology in the right manner for getting insights and analyzing the market for a better product-market fit. We can scrape info from the E-commerce website for getting information such as product pricing and reviews.
In this blog, we will be discussing how can we scrape product pricing and review links from Amazon. This is strictly for educational purposes and we recommend you to check the FAQ of web scraping before reading ahead this article. For this, we will be using Python and some open source libraries to serve our purposes such as Requests and SelectorLib.
Packages to install for Amazon Data Scraper
-
Requests
It is an open-source python package that is used to make HTTP requests and download the contents of the page which is the amazon product page in our case.
-
SelectorLib
It is a python package that is promptly used to extract data using the YAML file.
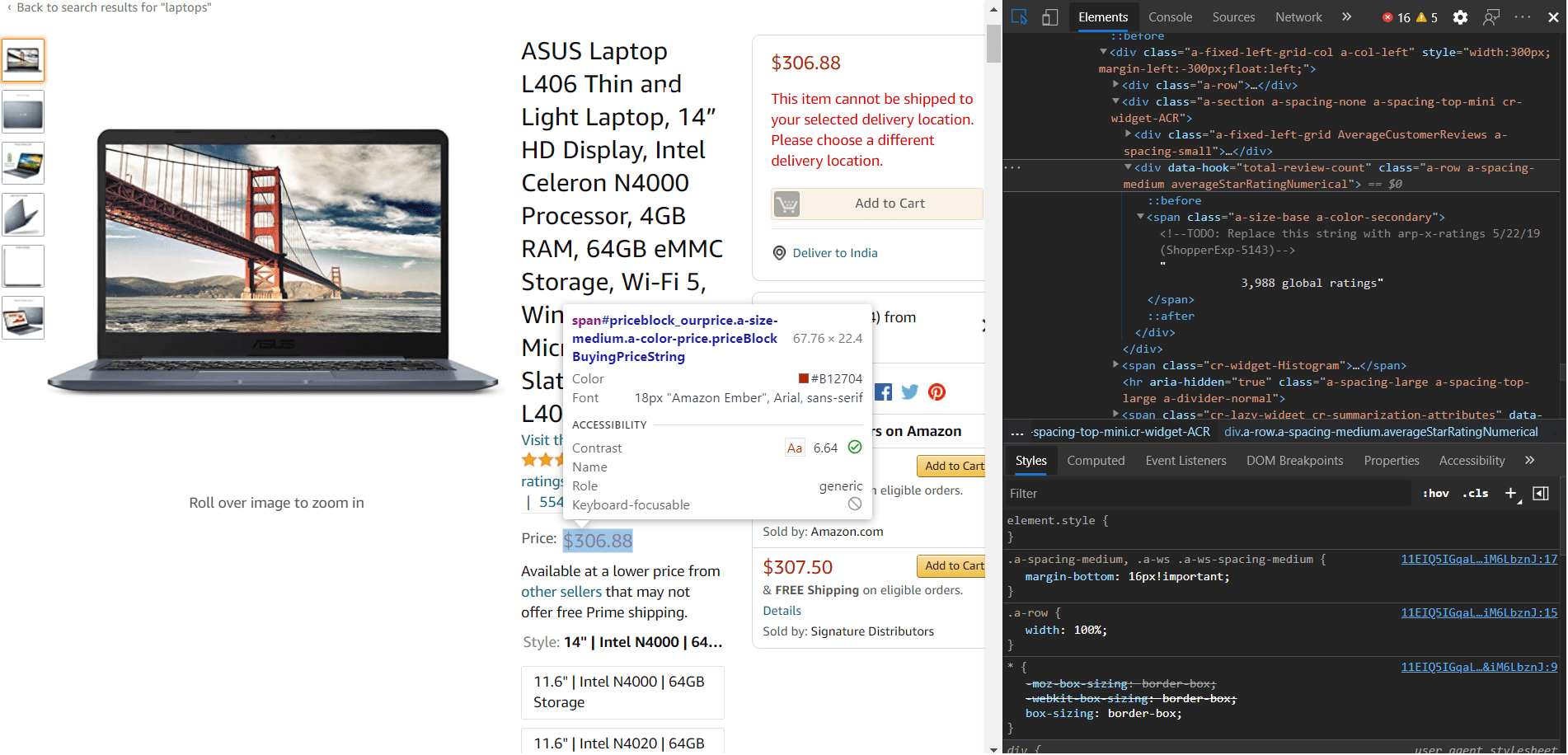
amazon-search-page
For this task, we will be focusing on extracting the following details from the particular product page.
- Name
- Price
- Product Images
- Product Description
- Link to reviews
4 Steps to create Amazon Data Scraper using Python
-
Let’s start with the HTML structure in the Selector.yml file
We should first start to create a selector.yml file that will contain all our CSS tags and HTML structure type and attributes. For this, we will need to select areas using inspect element or developer tools using any browser. After carefully selecting an attribute you can save all the information in the selector.yml file. For reference, we have added the code for the tags below.
name: css: '#productTitle' type: Text price: css: '#price_inside_buybox' type: Text images: css: '.imgTagWrapper img' type: Attribute attribute: data-a-dynamic-image rating: css: span.a-icon-alt type: Text product_description: css: '#productDescription' type: Text link_to_all_reviews: css: 'div.card-padding a.a-link-emphasis' type: Link -
Create a url.txt file to add links for the items
Now as we are done with the tags we can now add all the links for the pages in a urls.txt file. On carefully inspecting we found the HTML structure is the same for all the pages. Below you can see the urls.txt file.
https://www.amazon.com/ASUS-Display-Processor-Microsoft-L406MA-WH02/dp/B0892WCGZM/ https://www.amazon.com/HP-15-Computer-Touchscreen-Dual-Core/dp/B0863N5FM8/
-
Starting with the main Python script to utilize these files
Now as we are done with all the basic requirements we should now focus on the python script which will run these two files. Before this make sure all the dependencies are satisfied prior. We will be using Requests to get data from the webpage. For using the selector.yml file we will require selectorlib library and its extractor function which could be passed as a header in requests.get().
-
from selectorlib import Extractor import requests import json # Create an Extractor by reading from the YAML file e = Extractor.from_yaml_file('selectors.yml') def scrape(url): headers = { 'authority': 'www.amazon.com', 'pragma': 'no-cache', 'cache-control': 'no-cache', 'dnt': '1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp, image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'sec-fetch-site': 'none', 'sec-fetch-mode': 'navigate', 'sec-fetch-dest': 'document', 'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8', } # Download the page using requests print("Downloading %s"%url) r = requests.get(url, headers=headers) # Simple check to check if page was blocked (Usually 503) if r.status_code > 500: if "To discuss automated access to Amazon data please contact" in r.text: print("Page %s was blocked by Amazon. Please try using better proxies\n"%url) else: print("Page %s must have been blocked by Amazon as the status code was %d"% (url,r.status_code)) return None # Pass the HTML of the page and create return e.extract(r.text) with open("urls.txt",'r') as urllist, open('output.json','w') as outfile: for url in urllist.readlines(): data = scrape(url) print(data) if data: print(data) json.dump(data,outfile) outfile.write("\n") -
Generating output.json file as a result
Now we are using requests for getting the HTML content and with the defined content in the ‘header’ dictionary and if we have the content we will be extracting all the tags using the extractor() function. and return the dictionary. After returning we will be writing this to an ‘output.json’ file.
So this is how you can scrape the Amazon product page with this Amazon Data Scraper for improving your product and get insights whether it is customer sentiments or competitor pricing. There are other possible ways also which can be useful for your case but when we are using scraping there are a lot behind the scenes things that we need to consider like proxy service, user agent rotation, captcha solving, etc. This is where ScrapingPass comes into play. We will take care of all these roadblocks so you can focus on improving your product while leveraging our services.



Abhishek Kumar
More posts by Abhishek Kumar